 使用开源AI模型Whisper为视频生成字幕
使用开源AI模型Whisper为视频生成字幕
# 使用开源AI模型Whisper为视频生成字幕
Whisper是openai推出的一种通用语音识别模型。 它是在大量不同音频数据集上进行训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
官方网站: https://openai.com/research/whisper (opens new window)
GitHub 地址: https://github.com/openai/whisper (opens new window)
# Whisper环境配置
openai使用 Python 3.9.9 和 PyTorch 1.10.1 来训练和测试这个模型,但代码库预计与 Python 3.8-3.11 和最新的 PyTorch 版本兼容。
# python 下载安装
本次使用的是 Python 3.10.10
官方网站: https://www.python.org/downloads/windows/ (opens new window)
下载地址: https://www.python.org/downloads/release/python-31010/ (opens new window)
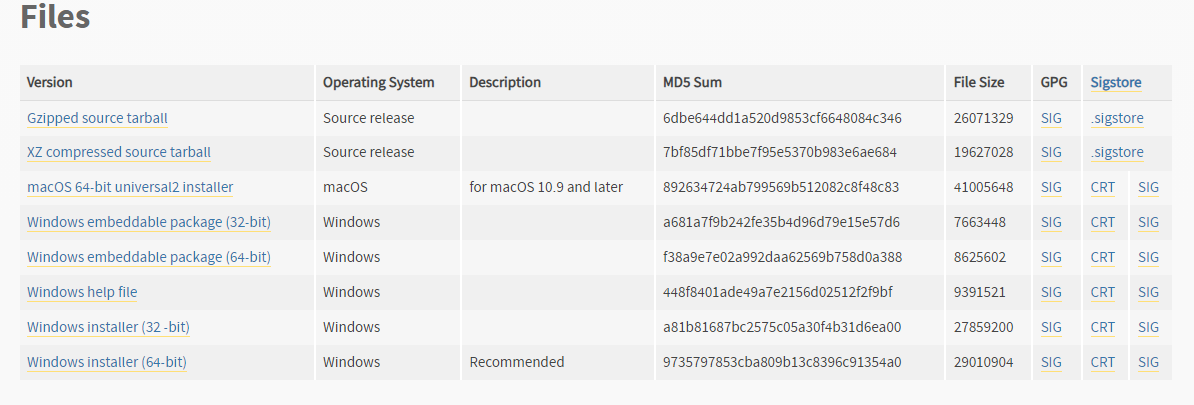
选择Windows installer (64-bit),之后按照提示逐步安装即可。
或者选择 Windows embeddable package (64-bit),解压后,手动配置目录到环境变量。
验证安装成功:
PS > python --version
Python 3.10.10
2
# 配置python虚拟环境(可选)
虚拟环境在Python中的好处包括依赖隔离,允许项目使用特定的依赖版本,并提供环境隔离,确保项目变更不影响系统其他部分。
选择一个目录,在这个目录打开powershell。
创建虚拟环境的命令:
python -m venv myvenv
- 在powershell中激活python虚拟环境:
.\myvenv\Scripts\Activate.ps1
- 验证是否激活了python虚拟环境:
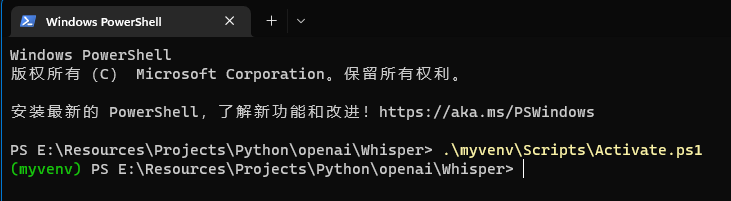
如图,如果有绿色的(myvenv),则代表进入了python虚拟环境。
# 安装Whisper
可以使用以下命令下载并安装(或更新到)最新版本的 Whisper:
pip install -U openai-whisper
验证Whisper安装成功:
> whisper --help
usage: whisper [-h] [--model MODEL] [--model_dir MODEL_DIR] [--device DEVICE] [--output_dir OUTPUT_DIR]
[--output_format {txt,vtt,srt,tsv,json,all}] [--verbose VERBOSE] [--task {transcribe,translate}]
[--language {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,r
...
2
3
4
5
# 安装ffmpeg
whisper依赖于ffmpeg来处理音视频的编解码。
# ffmpeg官网提供的安装方法
FFmpeg仅提供源代码。下面是一些链接,其中提供了已编译好的二进制文件。
https://ffmpeg.org/download.html#build-windows (opens new window)
下载完需要把目录手动添加到环境变量。
# openai官方提供的安装方法
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg
2
# 这需要先安装scoop
- 新打开一个powershell:
# Scoop 安装命令 (https://scoop.sh/)
> Set-ExecutionPolicy RemoteSigned -Scope CurrentUser # Optional: Needed to run a remote script the first time
> irm get.scoop.sh | iex
2
3
- 验证scoop安装成功:
> scoop help
Usage: scoop <command> [<args>]
Available commands are listed below.
Type 'scoop help <command>' to get more help for a specific command.
Command Summary
------- -------
alias Manage scoop aliases
...
2
3
4
5
6
7
8
9
10
11
# 验证ffmpeg安装成功
> ffmpeg --version
ffmpeg version N-106759-g987d2c1083-20220501 Copyright (c) 2000-2022 the FFmpeg developers
built with gcc 11.2.0 (crosstool-NG 1.24.0.533_681aaef)
2
3
# Whisper的使用
# 快速使用
解析MP4视频生成字幕(CPU计算,模型默认small,可以自动检测语言)
whisper 01.mp4
它会生成以下字幕文件:
01.json 01.srt 01.tsv 01.txt 01.vtt
# 使用GPU加速
需要安装CUDA:请参考 机器学习pytorch虚拟环境搭建 (opens new window)
whisper 01.mp4 --device cuda
# 使用其他模型
whisper 01.mp4 --device cuda --model medium
# 可用的模型和语言
有五种不同大小的模型,其中四种为仅支持英语的版本,提供速度和准确性的权衡。以下是可用模型的名称及其大致内存需求和相对于大模型的推断速度;实际速度可能因多种因素而异,包括可用硬件。
| 大小 | 参数 | 仅英语模型 | 多语言模型 | 所需显存 | 相对速度 |
|---|---|---|---|---|---|
| 微型 | 39M | tiny.en | tiny | ~1 GB | ~32倍 |
| 基础 | 74M | base.en | base | ~1 GB | ~16倍 |
| 小型 | 244M | small.en | small | ~2 GB | ~6倍 |
| 中型 | 769M | medium.en | medium | ~5 GB | ~2倍 |
| 大型 | 1550M | 无 | large | ~10 GB | 1倍 |
针对仅英语应用的.en模型通常表现更好,特别是对于 tiny.en 和 base.en 模型。对于 small.en 和 medium.en 模型,差异变得不那么显著。
# 后续工作
将字幕文件导入pr,合成带字幕的视频。
